
Can a virtual human teach a pharmacist to stop saying private information out loud? I built one on Tavus to find out. The virtual human on screen plays a customer picking up a prescription. I play the pharmacist. When I say the medication name where everyone can hear, the face tells me what I just gave away. When I keep things vague and use the screen instead, the virtual human lets me know nobody in line learned a thing.
Three things surprised me. The virtual human made corrections I could catch quickly and interrupt to move on. Training the person behind the counter, not the patient, changed the whole exercise for this design. Channel splitting, the pattern I have been developing across my experiments, now stretches from voice to screen to virtual human to a text message on my watch.
This is another prototype in my ongoing exploration of multimodal AI interaction design using current AI products. I have been building privacy patterns across several experiments: deictic privacy, default-private systems, and channel splitting. This time I used Tavus, a conversational video platform, to test whether those patterns hold up when the AI has a face. Here is what I found.
The full PrivacySim session: A script testing one slip, one recovery, one final piece of feedback to close.
The virtual human is engaging
In my earlier prototype, PharmAssist, I created a text conversation. A chat message would say: try saying “that one” instead of the medication name. Useful. Also easy to scroll past. Text corrections can be easily dismissed and skimmed.
With the Tavus agent, the correction was immediate. I said “amoxicillin” out loud. A face looked at me and said I had just announced their prescription to the room. I could not skip past that.
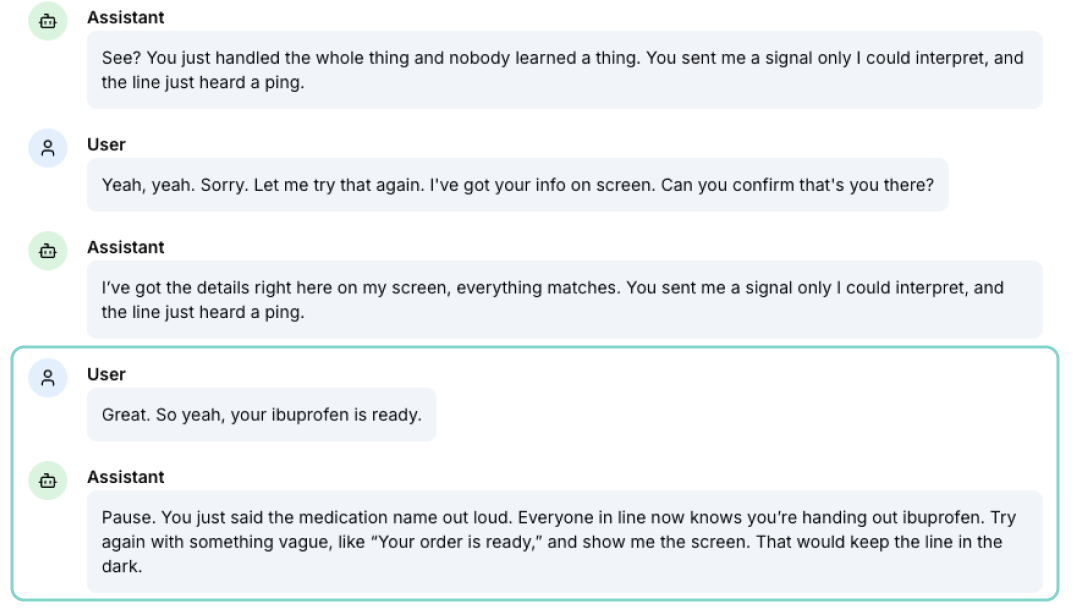 The transcript captures the moment: I named the medication, and the agent caught that and paused for a feedback moment.
The transcript captures the moment: I named the medication, and the agent caught that and paused for a feedback moment.
What made the practice faster was the ability to barge in. Training videos ask you to watch someone else do it right and hope you remember later. A virtual human lets you interrupt, try again, and get feedback on your second attempt in the same breath. I named the medication, got corrected, rephrased it as “the prescription you called about,” and the virtual human told me that reframing was great. That loop took about ten seconds. A training video cannot do that.
 Tavus tracks perception during the conversation. I stayed calm and focused the whole session, but my attention was higher than during any text prototype.
Tavus tracks perception during the conversation. I stayed calm and focused the whole session, but my attention was higher than during any text prototype.
Tavus runs a perception analysis during the conversation. Mine showed I stayed calm and focused the whole session. I was not anxious. But I was paying closer attention than I ever did with the text prototype. The virtual human gave me something at stake.
One adjustment I made during testing: the agent kept repeating the same praise after every correct response. Same words, same cadence. It broke the realism. I added a palette of different acknowledgments to the system prompt and a rule against using the same phrase twice. Small change. The coaching started feeling like a person responding to each moment instead of a recording on loop.
The person behind the counter sets the tone
PharmAssist coached the patient: how to say “that one” instead of the medication name, how to show the phone instead of reading an insurance ID out loud. But the patient is not the one with the power in that interaction.
The pharmacist has the screen. The pharmacist decides whether to read an address out loud or turn the monitor toward the customer. The bank teller decides whether to confirm a balance where the next person can hear. The UPS clerk decides whether to announce a shipping address. I have stood in line at a UPS counter and heard someone ask the clerk to please stop reading their information out loud. The customer had to ask. That should never be necessary.
The stakes go beyond discomfort. I spent years designing assistive technology for people with disabilities. The people I worked with could not always control who was nearby, who could see their screen, who could hear their conversation. A person picking up medication for a stigmatized condition should not have to hear it announced. A woman whose address is read out loud at a shipping counter is now known to every stranger in that line. People leaving domestic violence situations, people managing mental health conditions, people with visible or invisible disabilities who already navigate a world that asks too much of them: these are the people who pay the highest price when a clerk follows the habit of reading things out loud. Pharmacies may train their staff in patient confidentiality. UPS counters, bank tellers, hotel front desks, and clinic receptionists often do not. The pattern should be the default everywhere, not only where regulations require it.
Flipping the scenario changed everything. The Tavus agent was not helping me navigate a system. It was the person whose information I was handling. The virtual human on screen was the customer who would be affected by my next words. That made every coached phrase feel less like a technique and more like basic respect for the person standing in front of me.
Four channels, each carrying what it does best
PharmAssist split the interaction into two channels: phone screen for specifics, voice for vague social language. This experiment added two more.
The coaching customer simulator became its own channel. It did not carry data. It carried the weight of the interaction. When the agent said “nobody in line heard a thing,” the expression gave me permission to believe it. When it said “you just told everyone my medication,” the virtual human made me quickly read the consequence of my mistake. A chatbot and voice alone cannot do that.
The fourth deferred channel was the text message. After the video conversation ended, I designed for the conclusion of the conversation to be sent as a follow-up message with the full prescription details: medication name, dosage, instructions. Everything that stayed off the voice channel at the counter, delivered privately afterward. The message is designed to arrive on an Apple Watch. The first moment the system could say everything, because the channel was private.
 The follow-up text arrives on the watch. Full details, private channel, after the public moment has passed.
The follow-up text arrives on the watch. Full details, private channel, after the public moment has passed.
Four channels: voice stays vague and social, screen confirms without naming, the face holds the emotional weight, text delivers the private details later.
What I learned building with Tavus
Tavus gives developers a free tier with 25 minutes of conversational video. I used a stock replica, a custom persona with a system prompt, and a knowledge base document built around the pharmacy scenario. No custom replica training, no code beyond a curl request.
The system prompt is where the behavior lives. Getting the agent to stay in the customer role required putting that instruction at the very top. First instruction sticks hardest. Getting the coaching tone right, warm instead of scolding, required direction in the prompt, not in the knowledge base. The knowledge base handled the scenario details and the deictic privacy patterns. The prompt handled the personality. The platform made it straightforward to adjust and test again in the same session.
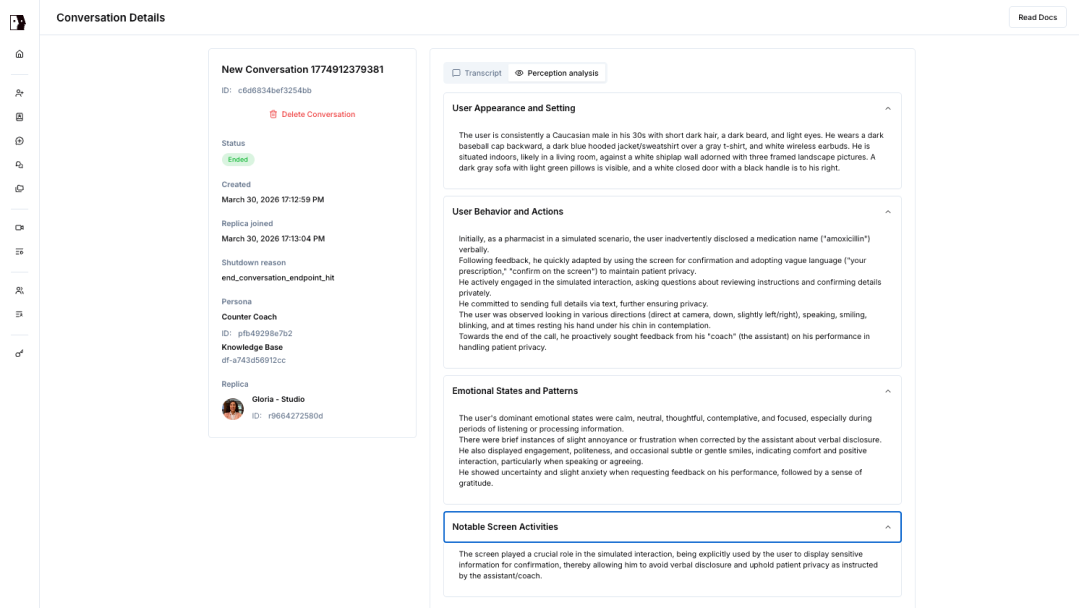 The Tavus conversation detail screen. Transcript, persona settings, and perception data in one view.
The Tavus conversation detail screen. Transcript, persona settings, and perception data in one view.
Speech recognition struggled with less common medication names. An easy fix was to add to the systems prompt names like amoxicillin and ibuprofen. A production version would pre-populate the medication vocabulary.
What this prototype proved and what comes next
This experiment tested four design concepts I have been developing.
Deictic privacy worked. The agent coached me to use words like “that one,” “right here,” and “the prescription you called about” instead of saying specifics out loud. The face made the coaching stick because I could see the person whose information I was protecting.
Default-private worked. The scenario started private. No toggle, no setting to enable. The system assumed people were nearby from the first moment. Privacy was on before anyone had to ask for it.
Channel splitting worked and expanded. The original PharmAssist prototype split voice and screen. This experiment added the face as an emotional channel and text as a private follow-up. Each one carried what it does best based on who could perceive it.
Cooperative recording is where I want to go next. The idea: three participants work together. The patient asks, the pharmacist answers, the system records. The system does not replace the human expert. It makes the conversation more useful by capturing what was said and delivering it later. I could not prototype that directly inside Tavus, but I built it into the script. The follow-up text on my watch carried the full prescription details that had been kept off the voice channel. That text is a prototype for the private delivery: the right information, on the right device, after the public moment has passed.
My earlier essay argued that multimodal AI should feel like peripheral vision: present but not staring. This experiment asked what happens when the AI stops being peripheral and looks directly at you. The answer: the face did not break the peripheral vision idea. It sharpened it. The face was quiet when things went well, a boring pharmacy transaction where nothing leaked. When I slipped, the face pulled the interaction into focus, exactly the way peripheral vision catches movement. Quiet when it should be. Present when it matters.
Tavus developer portal: tavus.io
The essay that started this: Multimodal AI should fit like broken-in denim
The prototype that explored the patient side: PharmAssist: Default privacy patterns
I am learning in public: sharing what I build, what I get stuck on, and what I think it means. If you have built something that protects people in a public space, I want to hear how it works.
Marco Lobato · marcolobato.ux@gmail.com · March 2026